 By Jonesy44 on Apr 07, 2009
By Jonesy44 on Apr 07, 2009Regex?
Regex (Regular Expressions) is an advanced search/find function in a string of text/unicode.
How does this tool help?
This tool simply helps by letting you enter the string of text to "search" then entering the expression to match it with. It will return whether a match was found. and the sections to be returned (regml(x)). This makes it easy to find the section you want
Extras
It also has a "notepad" so you can put your own notes in, this is helpful since there are MANY identifiers and denoations for regex. even I, the god of everything cannot remember everyone of them
Instructions
Load the script into remotes (Alt+R). Usage is /rxt [$regex(string,exp)]
Updates
V1.0
Screenshot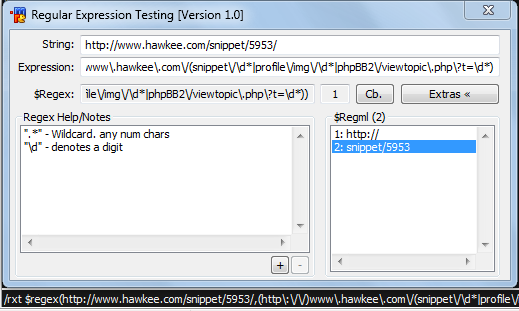
; ===============
; Regular Expression Testing
; By:Jonesy44
; Version:1.1
; ===============
alias -l rxt.version return 1.1
alias rxt {
dialog $iif($dialog(rxt),-v,-m) rxt rxt
if ($regex($1-,/\$regex\((.*),(.*)\)/)) { did -ra rxt 201 $regml(1) | did -ra rxt 202 $regml(2) | rxt.u }
}
alias -l rxt.u {
did -ra rxt 203 $+($chr(36),regex,$chr(40),$+($did(rxt,201),$chr(44),$did(rxt,202)),$chr(41))
did -ra rxt 204 $iif($regex($did(rxt,201),$did(rxt,202)),1,0)
did -ra rxt 302 $!Regml $+($chr(40),$regml(0),$chr(41))
did -r rxt 502
if ($regml(0)) { var %x = 1 | while (%x <= $regml(0)) { did -a rxt 502 %x $+ : $regml(%x) | inc %x } }
did -z rxt 502
}
alias -l rxt.h {
did -r rxt 501 | var %x = 1
while (%x <= $lines(regexhelp.dat)) { $iif($read(regexhelp.dat,%x),did -a rxt 501 $v1) | inc %x }
did -z rxt 501
}
dialog rxt {
size -1 -1 500 82
option pixels
title Regular Expression Testing $+([Version,$chr(32),$rxt.version,])
text "String:", 101, 5 7 60 13, right
text "Expression:", 102, 5 30 60 13, right
text "$Regex:", 103, 5 57 60 13, right
edit "", 201, 70 5 420 20, autohs
edit "", 202, 70 27 420 20, autohs
edit "", 203, 70 54 235 20, read autohs
edit "0", 204, 310 54 30 20, read center autohs
box "Regex Help/Notes", 301, 5 80 300 168
box "$Regml (0)", 302, 315 80 175 168
button "Extras »", 401, 390 53 100 22
button "Cb.", 402, 345 53 40 22
list 501, 10 95 290 128, vsbar hsbar size
list 502, 320 95 165 160, vsbar hsbar
button "+", 601, 260 225 20 20
button "-", 602, 280 225 20 20, disabled
}
on *:dialog:rxt:init:*: { dialog -s $dname -1 $calc($dialog(rxt).y - 84) 500 82 | rxt.h }
on *:dialog:rxt:sclick:*: {
if ($did == 401) { dialog -s $dname -1 -1 500 $iif($right($did(401),1) == »,250,82) | did -ra $dname 401 Extras $iif($right($did(401),1) == »,«,») }
elseif ($did == 402 && $did(203)) { clipboard $did(203) | noop $input(The regular expression identifier has been sent to the clipboard. Recall it using the "paste" function,io,Regex - Sent to Clipboard) }
elseif ($did == 501) { did $iif($did(501).seltext,-e,-b) $dname 602 }
elseif ($did == 601) { write regexhelp.dat $$input(Your reg-ex note to add to file:,eq,Regex - Adding a note) | rxt.h }
elseif ($did == 602) { write $+(-dl,$did(501).sel) regexhelp.dat | did -b $dname 602 | rxt.h }
}
on *:dialog:rxt:dclick:501: { write $+(-l,$did(501).sel) regexhelp.dat $$input(Your reg-ex note to edit:,eq,Regex - Adding a note,$did(501).seltext) | rxt.h }
on *:dialog:rxt:edit:201-202:rxt.u

This document might help with understanding mIRC regex:
http://www.mircscripts.org/showdoc.php?type=tutorial&id=989
Special Character Definitions
Note: not all of these may apply to mIRC but the vast majority do.
\ Quote the next metacharacter
^ Match the beginning of the line
. Match any character (except newline)
$ Match the end of the line (or before newline at the end)
| Alternation
() Grouping
[] Character class
---unsure about these---
{n} Match exactly n times
{n,} Match at least n times
{n,m} Match at least n but not more than m times
\t tab (HT, TAB)
\n newline (LF, NL)
\r return (CR)
\f form feed (FF)
\a alarm (bell) (BEL)
\e escape (think troff) (ESC)
\033 octal char (think of a PDP-11)
\x1B hex char
\c[ control char
\E end case modification (think vi)
\Q quote (disable) pattern metacharacters till \E
\A Match only at beginning of string
\Z Match only at end of string, or before newline at the end
\z Match only at end of string
\G Match only where previous m//g left off (works only with /g)

looks nice, this might inspire me to learn regex. I don't know if this would be possible (and it would probably be very difficult to make) but what would be really cool is if you could set 2 variables, a pre and post..and then the script/program would tell you the regex needed to get from pre to post. Just a thought if anyone wants to try that :p
Anyway nice job and I'm sure I'll be using this in the future :)
Here's some basic stuff:
? - The question mark indicates there is zero or one of the preceding element.
- The asterisk indicates there are zero or more of the preceding element.
- The plus sign indicates that there is one or more of the preceding element.
. - Matches any single character.
| - Matches either the expression before or the expression after the operator.
^ - Matches the starting position within the string.
$ - Matches the ending position of the string.
[ ] - Matches a single character that is contained within the brackets. [abc] [a-c]
[^ ] - Matches a single character that is not contained within the brackets.
{m,n} - Matches the preceding element at least m and not more than n times. (n optional)
+like
Horizontal scroll doesn't work and you should write as plaintext


